基于LLVM开发编译器(02):词法分析原理
词法分析是传统编译器的第一个阶段,其作用在于读取源文件的字符,然后将这些字符组成一个一个符合特定程序语言的词素,最后生成输出一个有效的词法单元序列。那么,也就是说词法分析是一个将字符流转换为单词流的一个过程,而识别这些单词流为有意义的句子流的过程则交给了词法分析的下一个阶段——语法分析。那么,一个设计优良的编译器,也将只有词法分析器能有机会触摸到一个一个的字符。而词法分析器除了这个主要的任务以外,也往往做一下琐碎的其它任务,比如加行号列号等,而在C与C++编译器中,这样的任务往往是预编译器做的。而由于大部分编译教材都是介绍传统的词法分析,语法分析等流程,所以很多时候涉及到一些问题是预编译器问题的时候,却往往思考成了词法分析器的责任,如在我博客留言板就有这样的例子,读者可以点击查看,那是一个很不错的例子。
词法分析器会将每一个识别出来的词素进行归类,而归类的结果我们称其为词法单元。如词法分析器识别出来3.14这个词素,它将会把3.14归类为number这个词法单元,而3这个词素也将会在number这个词法单元,然则”hello”这样的词素则将会在identifier这个词法单元。而词法分析器归类的依据则是程序设计语法规范说明,也即我们经常谈到的语言标准。所以,编译器开发人员经常摆到桌子上的有两个参考资料:一是语言标准,二是编译原理。而其实,在我们实际生活中,也有类似的例子。如英语,其也有归类标准。每一个英语单词都有紧密连接的字符从左到右组成,空白符作为了分隔单词的终结符,而组成的这些单词意义则可以由字典查出来,而这里的字典对应我们的程序语言则是语言标准,而英语单词则对对应于了每一个词素,分隔英语的空白符也是大部分程序设计语言的分隔符。
然而,与英语不同的是,程序设计语言将会具有一个特殊的词法单元——关键字(Keywords),也叫做保留字(Reserved Words),如C++的new。虽然new这样的关键字也是符合了identifier的归类标准,但是词法分析器识别到new这样的字符时将会毫不犹豫的归类在关键字这个词法单元分类,而非identifier。而词法分析器要识别出这样的关键字,可以通过字典查找的方式(即识别到了一个identifier,然后在一个Keywords Table中进行查找匹配,如果可以找到就将其放到Keywords中,如果不能找到,则将其放在identifier)或者可以使用硬编码的方式嵌入到语法规则中(即可以把Keywords直接与词法单元归在一起,然后不必通过识别出identifier后再查找Keywords Table再做分类是Keywords或者identifier),而这个识别Keywords有人在Quora提问过,我也进行过回答,在这个回答中我也嵌入了一些代码进行阐述,可以参考这个链接,读者可以思考一下我在这个回答中的代码示例是用的上述两种方式的哪一种。
那么,词法分析器应该如何识别出词素组成词法单元呢?那么这里我将引入一个很重要的概念:有穷自动机(Finite Automaton),有穷自动机分为确定性有穷自动机(Deterministic Finite Automaton)和非确定性有穷自动机(Nondeterministic Finite Automaton)。其中前者简称为DFA,后者简称为NFA。在传统的编译教材中,会有大量篇幅讲DFA、NFA、正则表达式的转换,然而还加上Kleene’s Construction啊,Thompson’s Construction啊等方法来阐述怎么弄,而在我的这篇文章将不会提到,我们要做的是是人肉出状态机与词法分析器,那些转换对我们的意义不大。
那么,接下来,我们就来谈谈如何利用状态机来识别出一个一个的词素。首先,我们来举一个简单的关键字new吧,那么的状态机有几个状态s0, s1, s2, s3,其中s0是起始状态,s3是终结状态,s1与s2是转换状态。那么,这里的状态转移状态是这样的:
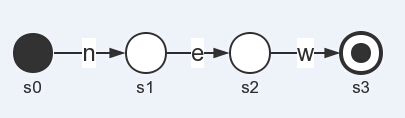
其思想非常简单,状态机首先处于s0起始状态,然后一直等待着到达s1状态的条件。当状态机接收到一个字符为n的时候,状态则从s0转移到s1了,当接收到字符为e的时候,则从s1转移到s2,随后接收到字符w的时候,则从s2转移到s3,而s3为终止状态,则状态机识别出了new这个词素。那么,有人可能问如果s0转移到s1后,接收到的字符不是e,而是其它字符,如h,那么状态机应该跑哪里去?这就要看你的设计了,你可以设计成跑到一个名叫se的错误状态,可以是其它的。如在大多数程序设计语言中,nh应该是属于identifier词法单元,那么在这里的状态机设计中就应该有一个支路指向identifier那边,所以一个词法分析器的状态机是由多种状态以及转移方程组成的,最后构成了一个“宏观”的状态机。
那么,接下来我们看看状态机如何识别数字单元,这里举例整形数字,而我举例整形则是为了引入新东西。整形数字包括0,123,12345454等这样的,而构成规则则是0,或者是开头为1~9,紧接着的数字由0~9构成的。其状态机图如下所示:
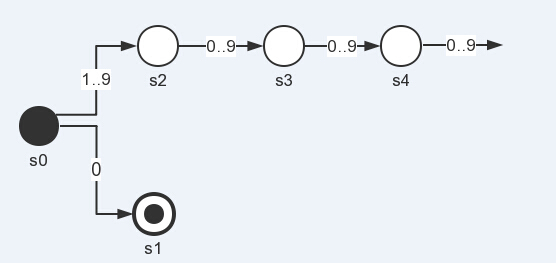
而这里可以看见问题所在,即上面的支路是没有终结状态,这显然是麻烦所在,没有终结状态,那么状态机就不知道什么时候可以“停下来”,那么怎么办呢?解决办法就是引入一个“弯箭头”,将这些公共的元素统一起来,如下图所示:
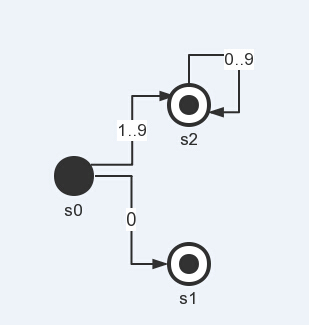
这样我们就有了终结状态。而程序好实现吗?很好实现,以前我们拿字符是nextChar方法,而有了弯箭头,我们加一个do…while循环套进去则可表达出来。为何是do…while而不是while?因为我们这里的转移是首先收到1..9转移到s2,而转移完毕后可能就不再执行(即没有跟随的数字位了),然而无论怎么样,都会首先执行一次转移到s2。
现在,让我们综合起来,做更复杂、有意义的状态机。在程序设计语言中,如果我们要表示一个identifier,则规则为起始为字母,随后跟随者若干字母或者数字,即[a-zA-Z][0-9a-zA-Z]*,这里的表示方法是正则表达式的方法,含义即为刚才说到的。我的博客并没介绍正则表达式,感兴趣的同学可以去搜索一下或者看看编译原理,而不介绍正则表达式的原因是我们接下来写的词法分析器并非如YACC这样的自动生成词法分析工具一样,我们是直接人肉暴力构造出状态机表示,而其实这样的人肉构造状态机的程序可读性,个人觉得其实比YACC这样的更好。言归正传,那么我们identifier的状态机则如下所示:
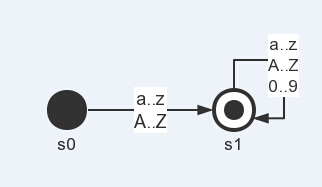
首先状态机会处于s0状态,直到遇到字母,然后转移到s1,而s1可以执行0到无数次,而执行的条件是数字或者字母,一直循环下去直到没有符合条件而停止。
词法分析的基本原理就差不多是这样,这里面少了许多过于学术化的东西,如前文提到的正则表达式、NFA、DFA的转换,以及DFA的数学表示等,但是我认为这对于我们的词法分析器构建并非有巨大的意义,而我们所需的是:如何能用计算机可以表达的模型,使用程序编写出词法分析器,这就是本文的重点。这样的例子也将出现在后续的语法分析中,如First集合与Follow集合这样的,我也不会讲,不过我会提及在哪里可以找到这样的内容,方便感兴趣的读者。
那么,接下来的一章就将是如何使用程序编写出我们词法原理对应的内容,从而构建出我们的词法分析器,而我也将会把代码放在GitHub上。这个编译器代码也是我从头开始随着教程开始写,讲一节写一节,方便随时反馈,我们下周末再见!
P.S. 这一篇文章距离上一篇文章已经比较久了,在我的留言板、知乎、邮箱、QQ、微博等都收到了很多询问我的博客的消息,我表示非常感动,毕竟发现有这么多的人来关注我的博客。而距离这么久,主要则是前段时间毕业比较的忙,而上周也正式的入职了,所以才拖到了现在。而现在的文章与教程我都会放在周末来写,比较固定。同时,这个教程将会比较大,涉及的内容比较多,因为我不想只是一个非常简单的编译器教学,这个编译器将会涉及很多内容,如数组、File、与C的库函数交互、I/O、以及编译器的代码生成与优化等内容,这些我都想在这个教程里面讲到,通过这样的方式,我相信读者也会都程序设计语言有更深的认识。虽然本教程不是讲C与C++,但是我相信你懂了该教程以后,可以写出自己的Mini C编译器。
(转载本站文章请注明作者和出处,请勿用于任何商业用途)