基于LLVM开发编译器(01):编译器概述
编译器是一个高度复杂的项目,同时也是非常重要的系统基础软件。人们对编译器也始终抱有浓厚的研究兴趣,无论是编译器前端部分的词法分析、语法分析、中间代码生成,抑或是编译器后端的目标代码生成、代码优化等均属于人们研究的范畴。而诸如你我的计算机学子或者IT从业人员,也都有着想做出一个编译器的想法。而与此相对的则是做出一个操作系统,这两个都是很多人想做的。
我也曾在想,为什么人们都想写一个编译器呢?也许是因为写编译器可以显得高大上?也许是因为写编译器可以有创造编程语言那样的“上帝”感觉?又或许是因为写编译器只是想更好的理解程序设计语言?但是,对于我来说,我最初写编译器的目的是想打开那个“黑盒子”,我喜欢那种追根溯源,然后恍然大悟的感觉,而这其实也是和我本科写操作系统的理由一样的。写完编译器,可以得到什么呢?我想一个益处就是别人看语言的时候,看到的是语法,而对于编译器开发者来说,第一直觉就是我知道如何实现它。如我最近在看号称人生苦短所需要的编程语言Python,Python中使用#进行单行注释,我脑海中的第一反应不是记忆住#对应着注释,而是#进行单行注释在词法分析器中如何实现。我想,这无疑是很快乐的学习,因为我都知道你这个在编译器如何设计了,那么我还有什么理由学不会呢?然而,实现一个完整的编译器的意义远远不止于此,因为设计实现一个编译器的过程中,能用到的知识很多,更像是一个计算机科学的缩影。它在寄存器分配中将会使用到贪心算法,死代码消除中将会使用到图论算法,数据流分析中使用到定点算法(Fixed-Point Algorithm),词法分析与语法分析中使用到有限状态机与递归下降这样的重要思想等等。是的,这是一个很有挑战与有意义的工作,完全值得我们去做。那么,有人或许会说单单5000行代码,能完成这么多工作吗?我会回答,关于优化算法的具体分析与实现,我会在后面的博客中书写(如Lazy Code Motion, Region-Based Analysis, Dynamic Code Optimization, Data Flow Analysis, Pointer Alias等),而我们这次仅仅是使用LLVM现成的优化算法而已(毕竟如上篇文章所述,这只是一个初学者的项目而已),然而有限状态机这样的重要思想却一定会是在这个项目中出现的。
那么回到正题,到底什么是编译器呢?概括的说,编译器是一个能将某种语言(源语言)编写的程序转换为另外一种语言(目标语言)的程序。是的,很确切的含义,这也是与操作系统的不同点,操作系统完全可以从各个角度来给出各种不同的定义。而编译器的主要目的则是将便于开发人员编写与阅读的高级程序语言(如C、C++、Pascal等)转换为另一种低级语言(如汇编语言),而产生的汇编语言将会通过汇编器转换为各种机器平台(如Intel 的x86平台,IBM的Power平台等)所能执行的机器语言,最后产生计算机可以执行的目标文件。而目标文件由于可以直接在计算机运行,所以目标文件也被成为可执行文件。而最著名的可执行文件包括Windows 操作系统的PE(Portable Executable)格式和类UNIX系统的ELF 格式(Executable and Linkable Format)。
编译器也是一个高度结构化的软件。从组织结构上,可以将编译器分为编译器前端与编译器后端。编译器前端主要包括了词法分析、语法分析、语意分析、中间代码生成部分,编译器后端则包括了分析与优化中间代码,进行目标代码的生成。然而发展到现在,其实在编译器前端与编译器后端的衔接处往往会有优化器层。优化器层的主要目的在于将前端产生的中间代码表示(Intermediate Representation,简称IR)进行分析与转换,从而产生更高效的代码,然后传给编译器后端。所以,很多时候编译器后端做的优化往往与目标平台有关了,而与机器无关的优化往往都在优化器层中进行,下图则展示了编译器的基本结构,图来源于Keith D. Cooper与Linda Torczon所著的《Engineering a Compiler》1.2节。
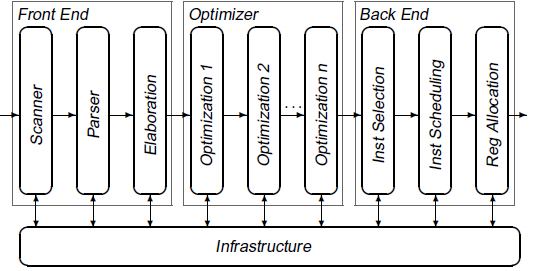
词法分析是编译器的第一个步骤,其所做的工作主要为将输入的代码转换为一系列符合特定语言的词法单元,这些词法单元类型包括了关键字,操作符,变量等。举个例子,Pascal语言包含了关键字if,那么在词法分析步骤时,遇到i与f组合在一起的时候,需要将这两个字母组合为关键字if这个词法单元。
编译器的第二个步骤为语法分析,所做的工作则是将词法分析器所产生的一系列词法单元组合起来,以其验证是否符合特定语言的语法规则,并且产生抽象语法树(Abstract Syntax Tree)。举个例子,Pascal语言的全局变量声明语句的语法格式为 var variableName : variableType; 其中variableName代表变量名,如a。variableType代表变量类型,如Integer。那么var a : Integer; 则为一个合法的语法声明,然而var 1 : Integer; 则非一个合法的语法声明,因为1为数字类型,而这里需要一个变量名,那么语法分析器应该报错。而通常用于语法分析器的语法表达方法为上下文无关表示法(Context-free Grammar),有关上下文无关表示法与语法分析的更详尽解释将在后续的语法分析原理部分讲述。
而语义分析主要为收集类型信息,并将这些信息放入符号表或者抽象语法树中,以便在随后的中间代码生成过程中调用。而这里面一个重要工作就是类型检测与类型转换。如在数组中,规定下标需要整数类型。而在一些语言中,允许类型提升,如C/C++语言中的int类型向double类型的自动提升。
中间代码生成是整个编译器前后端联系的纽带,属于核心的地位。在从源语言翻译为目标语言的过程中,编译器可能会有一到多个中间表示,而这个中间表示也可以有多种的形式,这种形式包括了三地址表示法,IBM编译器的WCode,LLVM的LLVM IR等。而本文所探讨与实现的Pascal编译器,它的中间代码格式将会是LLVM IR。
代码优化则将会运用一系列优化算法与措施来让代码执行的更加高效,如下面的简单程序例子:
a := 1.0;
b := 5.0;
a := 2.0 + b + 1.5;在这儿,由于2.0与1.5均为常量,所以我们可以将2.0与1.5先结合,再与b进行相加。而由于b又是常量,所以,我们可以进行Constant Folding,从而直接将8.5赋予给a,而不需要再进行将b载入,与2.0相加,存储到一个临时寄存器0%,然后再载入0%与1.5相加。而这里面运用到的Constant Folding其实属于了Local Optimization里面的优化技术。
目标代码生成主要则是中间代码生成目标平台的汇编代码,而这与目标平台息息相关。如果真的要研究这些汇编代码,其实是一件非常繁琐的事情,但是很幸运我们拥有了LLVM,可以很轻易的将LLVM IR转化为x86, PowePC等平台的汇编代码。
接下来的工作则是通过汇编器与链接器(如GCC的as与ld)进行汇编加载,生成可执行的目标文件。
到现在,我们则将实现编译器的意义、整个结构与流程都梳理了一遍,从下一节开始我们将真正踏入编译器实现的世界:词法分析。不过还需要缓一缓,因为首先将会是词法分析的原理,然后再是程序实现。编译器是原理与实现高度结合的项目,没有理论基础,谈何程序实现呢?
(转载本站文章请注明作者和出处,请勿用于任何商业用途)